文章 #1127
直观的了解大语言模型
未分类AI
有个牛逼的网站:https://projector.tensorflow.org/
可以帮助直观的了解大语言模型里的语义空间的概念
1. LLM 的核心就是「高维嵌入空间」
- 不论是 单词、子词、句子,甚至图片、代码,LLM 在内部都会先把它们转换成高维向量(embedding)。
- 这些向量不是随便生成的,而是通过大量训练让语义相近的内容在空间上距离更近,语义不同的距离更远。
- 对 GPT 这种模型来说,这个空间可能是 数千维(比如 4096 维),人类直观上是看不到的。
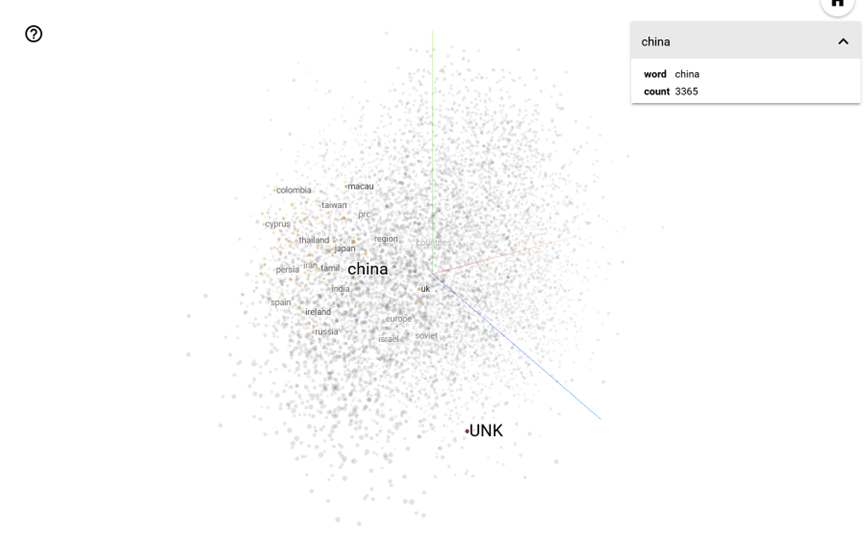
2. Embedding Projector 做的事
- 它把高维向量降维到 2D 或 3D,让你可以可视化这个语义空间。
- 这样你能看到词或概念的聚类,比如:
- “king” 和 “queen” 距离很近
- “Paris” 靠近 “France”,而 “Beijing” 靠近 “China”
- 如果是句子嵌入(Sentence Embeddings),你可以看到主题相近的句子会聚到同一区域。
历史评论
这些评论仅作只读保留。
这篇旧文没有已批准的历史评论。